Cómo Escalar Jobs y Colas en Laravel para Procesamiento Masivo de Imágenes
Procesar imágenes parece una tarea simple hasta que una aplicación comienza a trabajar con cientos o miles de archivos simultáneamente. En ese momento aparecen los verdaderos problemas: timeouts, workers bloqueados, consumo excesivo de memoria, colas saturadas y servidores completamente inestables.
Laravel ofrece herramientas extremadamente poderosas para resolver este tipo de escenarios, pero muchas aplicaciones siguen utilizando colas de forma superficial. Tener jobs no significa automáticamente que el sistema escale.
Escalar procesamiento masivo de imágenes requiere pensar en arquitectura distribuida, consumo de memoria, chunking, monitoreo y diseño correcto de pipelines.
En este artículo explicaré cómo construir pipelines escalables para procesamiento de imágenes en Laravel utilizando queues, Horizon, Redis y workers distribuidos desde una perspectiva práctica y enfocada en problemas reales.
El Error Más Común: Procesar Todo en un Solo Job
Uno de los errores más frecuentes ocurre cuando el desarrollador intenta procesar múltiples imágenes dentro del mismo job.
Por ejemplo:
foreach ($images as $image) {
// resize
// crop
// watermark
// save
}
Esto parece funcionar al inicio.
Pero conforme aumenta la carga aparecen problemas graves:
Timeouts
Uso excesivo de memoria
Bloqueo de workers
Procesos imposibles de reintentar parcialmente
Fallas completas por una sola imagen corrupta
Mi experiencia personal es que muchos sistemas colapsan no porque Laravel sea lento, sino porque los jobs fueron diseñados demasiado grandes.
Un job escalable debería representar una unidad pequeña, aislada y reintentable.
La Regla Más Importante: Un Job por Imagen
Cuando se trabaja con procesamiento pesado, la granularidad importa muchísimo.
En lugar de procesar 100 imágenes dentro de un job, es mucho más eficiente:
Un job por imagen
Un job por thumbnail
Un job por transformación específica
Por ejemplo:
ProcessImageJob
Y dentro:
public function handle()
{
// resize single image
}
Esto cambia completamente el comportamiento del sistema.
Ahora Laravel puede:
Distribuir carga
Paralelizar workers
Reintentar fallas individuales
Reducir memoria por proceso
Redis Cambia Todo
Laravel funciona perfectamente con base de datos como driver de colas, pero para procesamiento masivo Redis es prácticamente obligatorio.
La diferencia de rendimiento es enorme.
Redis permite:
Mayor throughput
Menor latencia
Workers concurrentes más rápidos
Mejor manejo de grandes volúmenes
Además Horizon está construido específicamente para aprovechar Redis.
Mi recomendación personal es simple:
Si el proyecto procesa imágenes intensivamente, usa Redis desde el inicio.
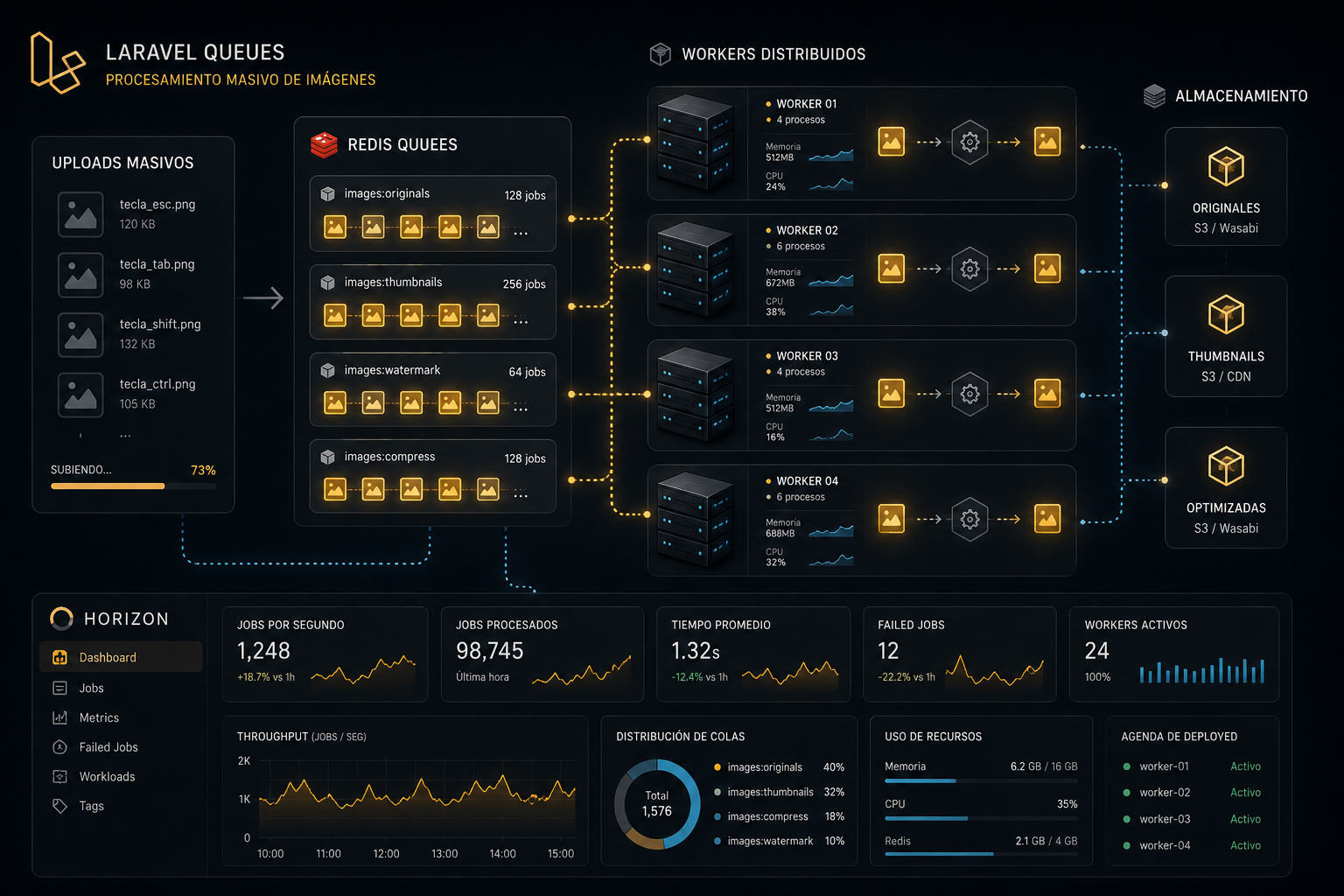
Horizon No Es Opcional en Sistemas Grandes
Muchos desarrolladores utilizan colas sin monitoreo real.
Ese es un error enorme.
Laravel Horizon ofrece:
Monitoreo en tiempo real
Throughput
Tiempo promedio de jobs
Failed jobs
Workers activos
Balanceo automático
Cuando un sistema comienza a procesar miles de imágenes, Horizon deja de ser una comodidad visual y se convierte en infraestructura crítica.
El verdadero valor de Horizon no es únicamente observar métricas.
Es detectar cuellos de botella antes de que destruyan el sistema.
Separar Colas por Tipo de Trabajo
Otro error extremadamente común es colocar todos los jobs en la misma cola.
Por ejemplo:
Emails
Procesamiento de imágenes
Notificaciones
Exportaciones
Todo mezclado.
Esto genera starvation.
Un procesamiento pesado puede bloquear tareas críticas.
Lo correcto es separar:
php artisan queue:work --queue=images
Y otra:
php artisan queue:work --queue=emails
Incluso es recomendable usar workers dedicados exclusivamente a imágenes.
El procesamiento multimedia suele tener comportamientos completamente distintos al resto del sistema.
Chunking: La Técnica que Evita el Colapso
Cuando se trabaja con miles de registros, cargar todo simultáneamente destruye memoria.
Laravel ofrece herramientas extremadamente útiles:
Image::query()->chunk(100, function ($images) {
// dispatch jobs
});
Esto permite:
Reducir consumo RAM
Evitar queries gigantes
Procesar progresivamente
El chunking es especialmente importante cuando existen pipelines de thumbnails o múltiples resoluciones.
He visto procesos morir simplemente por intentar cargar demasiadas imágenes en memoria.
El Problema Real: Memoria y CPU
Procesar imágenes consume muchísimos recursos.
No solamente almacenamiento.
También:
CPU
RAM
I/O de disco
Bibliotecas como Intervention Image o Imagick pueden consumir enormes cantidades de memoria dependiendo de la resolución.
Por eso es importante:
Liberar recursos rápidamente
No mantener imágenes en memoria innecesariamente
Reducir resoluciones cuando sea posible
Evitar múltiples transformaciones simultáneas
Mi recomendación es que cada worker procese tareas pequeñas y termine rápido.
Workers largos suelen ser mucho más inestables.
Workers Distribuidos
Uno de los mayores beneficios de queues es la capacidad de distribuir procesamiento horizontalmente.
Por ejemplo:
Servidor 1 procesa thumbnails
Servidor 2 procesa imágenes HD
Servidor 3 genera previews
Todos consumiendo la misma cola Redis.
Esto permite escalar sin modificar lógica de negocio.
Laravel maneja muy bien este enfoque.
La verdadera limitación normalmente no es el framework.
Es la arquitectura del pipeline.
Estrategias Anti-Timeout
Uno de los problemas más frecuentes en procesamiento pesado son los timeouts.
Especialmente cuando:
Las imágenes son gigantes
Existen múltiples transformaciones
El almacenamiento es lento
Algunas estrategias efectivas:
Jobs pequeños
Separar transformaciones complejas
Evitar loops masivos dentro del mismo worker
Incrementar timeout solo cuando sea realmente necesario
Usar pipelines encadenados
Por ejemplo:
Bus::chain([
new ResizeImageJob(),
new GenerateThumbnailJob(),
new WatermarkImageJob(),
]);
Esto mejora muchísimo la estabilidad.
El Poder de Batch Processing
Laravel permite agrupar jobs usando batches.
Esto es extremadamente útil para:
Procesamiento masivo
Seguimiento de progreso
Reintentos grupales
Notificaciones finales
Bus::batch([
new ProcessImageJob(),
new ProcessImageJob(),
])->dispatch();
Esto permite construir sistemas mucho más profesionales.
Especialmente cuando el usuario necesita saber:
Cuántas imágenes faltan
Cuánto progreso existe
Qué jobs fallaron
El Error Silencioso: No Monitorear Failed Jobs
Muchos sistemas fallan silenciosamente.
El usuario sube imágenes.
Algunas no se procesan.
Y nadie lo detecta.
Eso es peligrosísimo.
Todo sistema serio debería monitorear:
Failed jobs
Tiempo promedio
Picos de procesamiento
Consumo de workers
Tasas de error
Horizon ayuda muchísimo aquí.
Pero además recomiendo:
Alertas
Logs estructurados
Dashboards internos
Conclusión
Escalar procesamiento de imágenes no consiste únicamente en activar queues.
Consiste en diseñar pipelines resilientes.
Laravel ofrece herramientas extremadamente potentes:
Queues
Redis
Horizon
Batching
Chains
Workers distribuidos
Pero la verdadera diferencia aparece cuando el sistema está correctamente fragmentado.
Mi experiencia personal es que muchos problemas de rendimiento nacen porque los jobs intentan hacer demasiado.
Mientras más pequeño, aislado y específico sea un job, más fácil será escalarlo.
Laravel puede manejar pipelines extremadamente complejos si la arquitectura está bien diseñada.
Y en sistemas multimedia grandes, esa arquitectura es mucho más importante que cualquier optimización aislada.